linux_network_1
socket的创建
1 | SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol) |
内核和用户进程之间阻塞
同步阻塞/recvfrom
1 | 同步阻塞的开销主要有: |
多路复用epoll
1 | epoll_create |
1 | 本质上是 极大程序的减少了无用的进程上下文切换,让进程更专注处理网络请求。 |
1 | epoll也是阻塞的。没有请求处理的时候,也会让出CPU。阻塞不会导致低性能。过多的阻塞才会。W |
阻塞 非阻塞
阻塞指的是进程因为等待某个事件而主动让出CPU挂起的操作。在网络IO中。当进程等待socket上的数据时,如果数据还没有到来,那就把当前状态从TASK_RUNNING修改为TASK_INTERRUPTIBLE。然后主动让出CPU,由调度器来调度下一个就绪状态的进程来执行。
所以,以后分析是否阻塞就看是否让出CPU。
内核是如何发送网络包的?
网络包发送过程总览
用户进程在用户态通过send系统调用接口进入内核态,send通过内存拷贝skb,进程协议处理进入驱动ring buffer,通过pci总线发送后,产生中断通知发送完成,并清理ring buffer。
1 | send |
数据发送完毕后,释放缓存 队列等内存。在网卡发送完毕后,给CPU发送一个硬中断来通知cpu。实际是触发了 NET_RX_SOFTIRQ 。所以服务器中proc softirqs里面NET_TX要比RX大很多。
网卡启动准备
网卡启动最重要的任务之一就是分配和初始化RingBuffer。在对应的驱动程序的open函数中,对于ringbuffer进行分配。
1 | igb_setup_all_tx_resources |
为什么要用环形队列?好处是什么
| 特性/对比点 | 环形队列(Ring Buffer) | 普通 FIFO 队列(如链表) |
|---|---|---|
| 内存分配方式 | 预分配,连续内存块 | 动态分配,每个节点独立分配 |
| 缓存命中率 | 高(连续内存 + 局部性好) | 低(指针跳转 + 内存分散) |
| 指针操作复杂度 | 简单,仅需要 head 和 tail | 操作复杂,涉及节点申请/释放 |
| 支持无锁操作 | 易于 lockless 实现,尤其单生产者/单消费者模型 | 难,容易涉及竞态和锁 |
| 空间使用效率 | 高,数组固定大小,空间紧凑 | 较低,节点指针额外开销 |
| 硬件 DMA 支持 | 很多硬件直接支持环形 DMA 描述符结构 | 不适用于 DMA 映射 |
| 数据结构大小固定性 | 是,数组固定大小,易于调优和估算 | 否,链表大小动态变化,管理麻烦 |
| 实现难度 | 结构简单,逻辑清晰 | 相对复杂,需要考虑链表指针等各种异常处理 |
数据从用户进程到网卡的过程
send系统调用实现
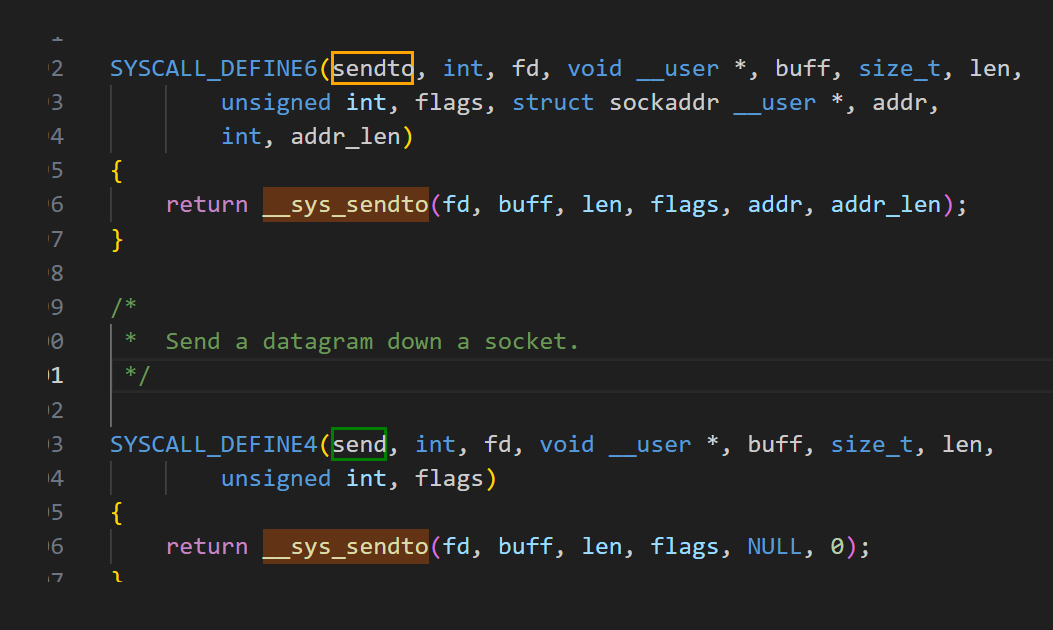
sendto中 构造 找到sock,构造msg后 通过 __sock_sendmsg 发送,到sock_sendmsg_nosec中,通过 inet6_sendmsg 调用进入协议栈。
传输层处理
在进入协议栈后,会找到具体的发送函数。对tcp来说是 tcp_sendmsg –> tcp_sendmsg_locked。 tcp_write_queue_tail获取发送队列的最后一个skb。把用户内存里的数据拷贝到内核态,涉及到1次/几次内存拷贝的开销。
1 | if (forced_push(tp)) { |
调用tcp_push_one / __tcp_push_pending_frames 将数据包发送出去。
最终会调用到。
1 | /* Send _single_ skb sitting at the send head. This function requires |
网络层发送处理
tcp_write_xmit内部处理了传输层的拥塞控制,滑动窗口相关的工作,满足窗口要求的时候,设置TCP头然后将skb传到更低的网络层进行处理。
tcp_transmit_skb开启真正的发送函数。clone新的tcp出来,封装tcp的头.
1 | /* Build TCP header and checksum it. */ |
为什么要进行clone? tcp支持超时重传, 在收到对方的ACK之前,这个skb’不能被删除.等收到ACK后再次删除.
tcp_options_write中对TCP头进行设置, skb中包含了网络协议中的所有头,在设置TCP的头的时候,只需要把指针指向skb的合适位置,后面设置IP头的时候,指针在挪一挪即可.避免频繁的内存申请拷贝.
1 | queue_xmit 在 ipv4中 实际值得是. |
邻居子系统
位于网络层和数据链路层中间的一个系统, 为网络层提供一个下层的封装, 让网络层不必关心下层的地址信息, 让下层决定发送到哪个MAC地址. 主要查找/创建邻居项,在创建邻居项的时候,可能会发出实际的ARP请求,然后封装MAC头,将发送过程传递到更下层的网络设备子系统.
调用 neigh_resolve_output 发出,有可能触发arp请求.
最后调用 dev_queue_xmit 将skb传递给Linux网络设备子系统
linux网络设备子系统
__dev_queue_xmit()
└── __dev_queue_xmit_xmit()
└── dev_hard_start_xmit()
└── xmit_one()
└── dev->netdev_ops->ndo_start_xmit()
总览
TX
1 | // 1.分配 sk_buff,复制用户数据 |
RX
1 | 1. 软中断 |
参考资料
https://blog.csdn.net/weixin_44260459/article/details/121480230