real time OS
实时操作系统,它通过调度和资源管理,保证实时任务在规定的时间限制内完成。
linux不是实时操作系统,主要是因为:
1 | 存在关中断机制,低优先级的进程如果关闭了中断(进入临界区等),高优先级的进程中断发生也无法响应。 |
RTlinux,后演变为preempt_rt,在linux的基础上打补丁,增加了
1 | 中断线程化:把传统硬中断 top-half 的大部分逻辑移到内核线程里运行。可以被调度,减少CPU被不可抢占硬中断占用的时间。 |
实时操作系统,它通过调度和资源管理,保证实时任务在规定的时间限制内完成。
linux不是实时操作系统,主要是因为:
1 | 存在关中断机制,低优先级的进程如果关闭了中断(进入临界区等),高优先级的进程中断发生也无法响应。 |
RTlinux,后演变为preempt_rt,在linux的基础上打补丁,增加了
1 | 中断线程化:把传统硬中断 top-half 的大部分逻辑移到内核线程里运行。可以被调度,减少CPU被不可抢占硬中断占用的时间。 |
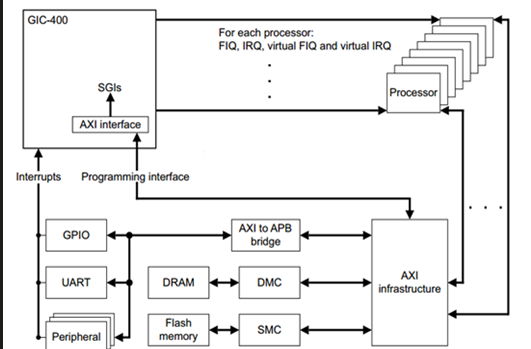
Generic Interrupt Controller。ARM提供的通用中断控制器。接受硬件中断信号,并经过一定处理后,分发给对应的CPU进行处理。分为V1-V4,
GIC是联系外设中断和CPU的桥梁,也是各CPU之间中断互联的通道,负责检测,管理,分发中断。
1 | 主要负责 |
ARM CPU对外的连接只有2个中断,IRQ & FIQ,相对应的处理模式分别是 IRQ 一般中断处理模式 和 FIQ 快速中断处理模式,所以GIC最后要把中断汇集成2条线,与CPU对接。
在GICV2中,gic由两个大模块distributor和interface组成。
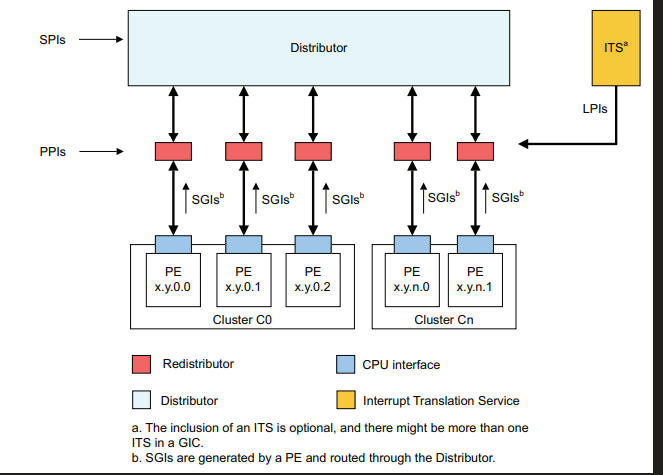
主要负责中断源的管理,优先级,中断使能,中断屏蔽等。中断分发,对于PPI,SGI是各个core独有的中断,不参与目的core的仲裁,SPI 是所有 core 共享的,根据配置决定中断发往的core。中断优先级的处理,将最高优先级的中断发送给cpu interface。寄存器使用GICD作为前缀,一个gic中,只有一个GICD。
主要的作用是检测各个中断源的状态,控制各个中断源的行为,分发各个中断源产生的中断事件到指定的一个/多个CPU接口上。虽然分发器可以管理多个中断源,但是它总是把优先级最高的那个中断请求送往CPU接口。分发器对中断的控制包括:
1 | 打开或关闭每个中断,Distributor对中断的控制分成两个级别,一个是全局中断的控制(GIC_DIST_CTRL),一旦关闭了全局中断,那么任何的中断源产生的中断事件都不会被传递到cpu interface。另一个级别是针对各个中断源进行控制,(GIC_DIST_ENABLE_CLEAR),关闭一个中断源会导致该中断事件不会分发到CPU interface,但不影响其他中断源产生中断事件的分发。 |
用于连接器,与处理器进行交互,将GICD发送的中断信息,通过IRQ,FIQ等管脚,传输给core。寄存器使用GICC作为前缀,每一个core,有一个cpu interface。
1 | 打开或关闭cpu interface 向连接的CPU assert中断事件,对于arm,cpu interface和cpu之间的中断信号线是nIRQCPU 和 nFIQCPU, 如果关闭了中断,即便是distributor分发了一个中断事件到CPU interface,也不会assert指定的IRQ或者FIQ通知core。 |
将GICD发送的虚拟中断信息,通过VIRQ,VFIQ管脚,传输给core,每一个core,有一个virtual cpu interface,而在这个virtual cpu interface中,又包含以下两个组件,virtual interface control,virtual cpu interface。
gicv2,将中断,分成了group0,安全,FIQ 和group1,非安全,IRQ。
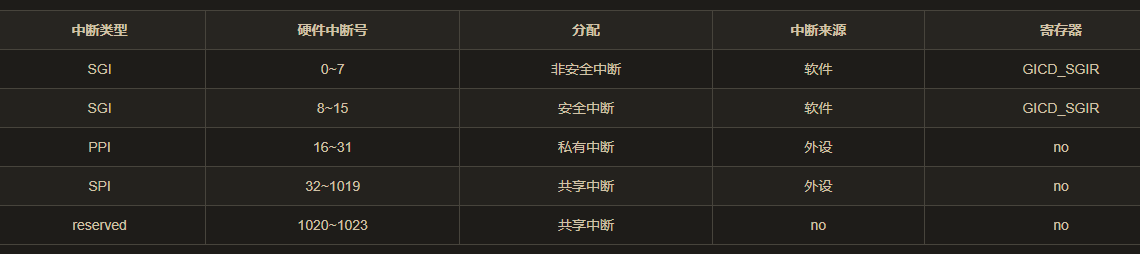
支持三种类型的中断。
1 | GICV2: |
GICV3的组成部分,GICV3中,主要由Distributor,cpu interface,redistributor,its,GICV3中,将cpu interface从GIC中抽离,放入到了cpu中,cpu interface通过AXI Stream,与gic进行通信。 当GIC要发送中断,GIC通过AXI stream接口,给cpu interface发送中断命令,cpu interface收到中断命令后,根据中断线映射配置,决定是通过IRQ还是FIQ管脚,向cpu发送中断。
1 | root@root:~# cat /proc/interrupts |
1 | GIC决定每个中断的 使能 状态,不使能的中断,是不能发送中断的 |
gicv2,支持最小16个,最大256个中断优先级。
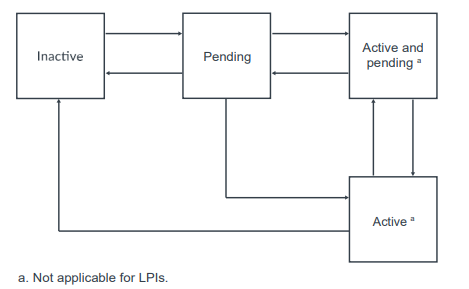
1 | 每个中断都维护了一个状态机。 |
1 | 主要分为四部分: |
1 | 常见术语 |
1 | gic: interrupt-controller@fd400000 { |
1 | IRQCHIP_DECLARE(gic_v3, "arm,gic-v3", gicv3_of_init); //初始化一个struct of_device_id的静态常量,并放置在__irqchip_of_table中 |
1 | https://doc.embedfire.com/linux/rk356x/driver/zh/latest/linux_driver/subsystem_interrupt.html |
上下文信息,既包含虚拟内存,栈,全局变量等用户态的资源,也包括内核堆栈,寄存器资源,不同类型的上下文切换,会涉及到不同类型的资源切换。
临界资源是一次仅允许一个进程使用的共享资源。各进程采取互斥的方式,实现共享的资源称作临界资源。
每个进程中访问临界资源的那段代码称为临界区(criticalsection),每次只允许一个进程进入临界区,进入后,不允许其他进程进入。显然,若能保证进程互斥地进入自己的临界区,便可实现诸进程对临界资源的互斥访问。
1 | 某个进程时间片耗尽,会被系统挂起,切换到其他等待 CPU 的进程。 |
1 | 同一进程内线程切换:由于线程共享进程的虚拟内存和大部分资源,调度器只需切换线程私有的寄存器、内核栈和调度信息,而不需要切换虚拟内存,因此开销较小、 |
1 | 中断上下文切换指的是为了响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将当前的状态保存下来。这样在中断结束后,进程仍然可以从原来的状态恢复运行。 |
运行在进程上下文的内核代码是可抢占的,但中断上下文会一直运行到结束,不会被抢占。所以中断处理程序代码要受到一些限制。
1 | 中断代码不能: |
Linux配置打开了CONFIG_PREEMPT表示允许高优先级的任务抢占低优先级任务,但是在spin lock,中断/软中断上下文中依旧不允许抢占的。在linux系统中使用了一个Per-CPU的32位变量来标识一些特殊场景,如下
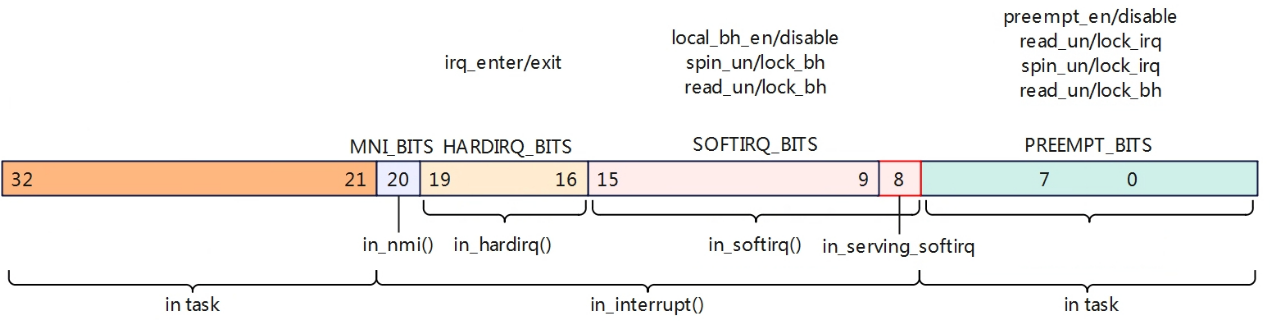
1 | enum { |
1 | // raise_softirq 触发软中断 |
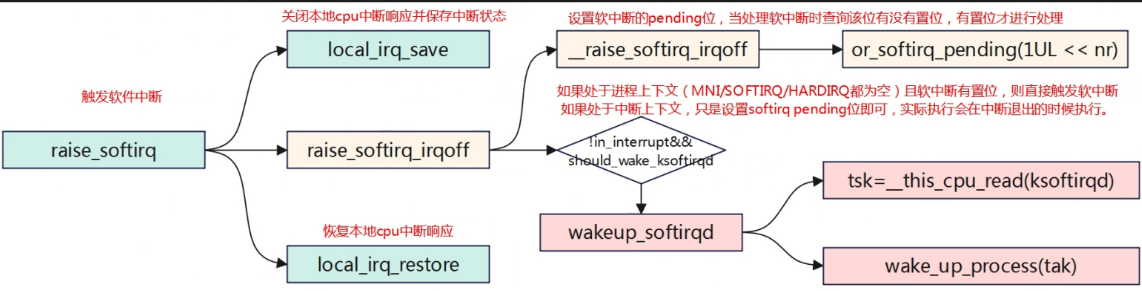
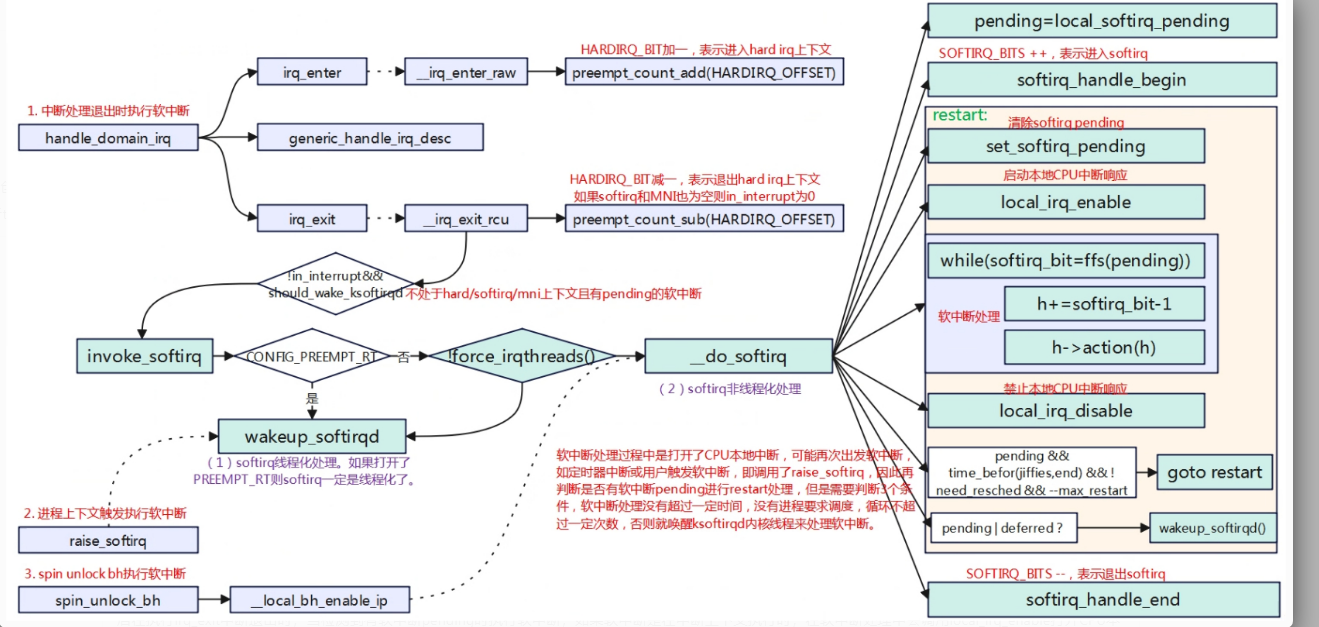
软中断执行时机分为三种,中断退出时检测是否有软中断执行,进程上下文中主动执行,spin_unlock_bh后执行。
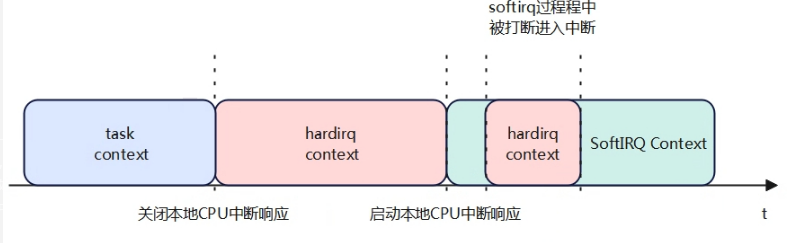
进程被中断打断后进入到中断上下文中,进入中断后cpu硬件会自动关闭cpu本地中断响应,处理中断完成后在执行irq_exit中断退出时,当检测到有软中断pending时执行软中断;如果软中断是在中断上下文执行时,在软中断处理中会调用local_irq_enable打开CPU本地中断响应再处理软中断程序,如果是触发的软中断线程,硬中断已经完成退出也会使能本地中断。因此在软中断执行过程中打开了中断响应,所以可能会再次进入硬中断上下文。
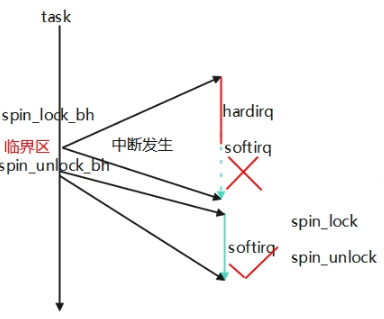
在一个task中处理一个变量此时被硬件中断打断进行中断处理函数,在中断处理快结束时如果有软中断pending将会先处理软中断,如果软中断中也访问了该变量,那么就出现竞态异常,因此为了处理进程和软中断的竞态,调用spin_lock_bh和spin_unlock_bh进行保护,在硬件中断处理完要进入软中断将会被禁止,硬件中断会被直接退出,继而task可以继续运行,当task再执行spin_unlock_bh时会触发执行软中断。另外如果软中断处理函数中的竞态可能在多核直接发生,为了保护多核的临界处理在软中断中只需要调用spin_lock和spin_unlock即可,不需要调用spin_lock_bh和spin_unlock_bh,因为每个cpu上只有一个软中断可以运行不需要做软中断之间的临界保护。总结就是在进程上下文中要避免软中断和多核的竞态保护就调用spin_lock_bh和spin_unlock_bh,软中断中避免多核的竞态保护就调用spin_lock和spin_unlock即可。
tasklet(小任务机制)是利用软中断实现的下半部机制。是softirq的特殊实现。Tasklet则是自身串行化的,同一时间只能有一个特定的tasklet在运行。
1 | open_softirq(TASKLET_SOFTIRQ, tasklet_action); |
软中断和tasklet都是运行在中断上下文中,它们与任一进程无关,没有支持的进程完成重新调度。所以软中断和tasklet不能睡眠、不能阻塞,它们的代码中不能含有导致睡眠的动作,如减少信号量、从用户空间拷贝数据或手工分配内存等。也正是由于它们运行在中断上下文中,所以它们在同一个CPU上的执行是串行的,这样就不利于实时多媒体任务的优先处理。
将下半部工作推迟,给一个内核线程去执行 ——work 总是运行于进程上下文.可以睡眠。允许被重新调度。
1 | 声明且初始化 |
1 | schedule_work(struct work_struct *work); |
1 | 普通 work |
1 | // 取消work 模块卸载退出时使用 |
1 | // 等待队列执行完成。常用于 模块退出时,确保没有遗留 work 在运行。 |
不能在中断上下文里 flush/cancel work,否则可能死锁
1 | // 自定义workqueue |
1 | // 提交work到自定义的队列 区别于 schedule_work:可选择具体的 workqueue。 |
1 | static struct workqueue_struct *my_wq; |
只有当无法向系统工作队列提交新的工作项时,才去创建额外的工作队列。因为每个新的工作队列都会花费可观的内存占用。如果新工作队列中的工作项无法与系统工作队列中已存在的工作项共存时,可以调整新的工作队列。例如,新的工作项执行了阻塞操作导致其它系统工作队列被延迟到一个不可接受的程序。
1 | 如果推后执行的任务需要睡眠,那么就选择工作队列;如果推后执行的任务不需要睡眠,那么就选择tasklet。 |
为什么linux不是实时操作系统
进入中断处理时,cpu就关闭了本地中断响应,没法再响应其他中断,即linux的中断是没法嵌套的,即使有在高优先级的中断也是没法处理。另外软中断的处理要比任何进程优先级高,因为软中断也是可以在中断上下文中运行。除了中断,软中断外,spinlock在处理过程中是关闭抢占调度的,所以在spinlock期间也是没法调度的。
真正实现都是在网卡驱动中,所以这个工具较为重要。
1 | -i 显示网卡驱动的信息,名称,版本等 |
包含了一些网卡统计信息
1 | RX packets:接收的总包数 |
1 | /proc/net/dev 下有节点可以统计网卡工作数据 |
当数据帧到达网卡,第一站即为RingBuffer,网卡通过DMA机制将数据帧送到RingBuffer中。因此第一个要监控和调优的就是网卡的RingBuffer.
ethtool -g eth0 可以查看Ringbuffer的大小。
在Linux的整个网络栈中,RingBuffer起到一个任务的收发中转站的角色。对于接收过程来讲,网卡负责往RingBuffer中写入收到的数据帧,ksoftirqd内核线程负责从中取走处理。只要ksoftirqd线程工作的足够快,RingBuffer这个中转站就不会出现问题。但是我们设想一下,假如某一时刻,瞬间来了特别多的包,而ksoftirqd处理不过来了,会发生什么?这时RingBuffer可能瞬间就被填满了,后面再来的包网卡直接就会丢弃,不做任何处理!
ethtool -S xx 或者 ifconfig xx都可以查看是否是因为这个原因丢包。
rx_fifo_errors如果不为0的话(在 ifconfig 中体现为 overruns 指标增长),就表示有包因为RingBuffer装不下而被丢弃了。那么怎么解决这个问题呢?很自然首先我们想到的是,加大RingBuffer这个“中转仓库”的大小。通过ethtool就可以修改。
1 | # ethtool -G eth1 rx 4096 tx 4096 |
这样网卡会被分配更大一点的”中转站“,可以解决偶发的瞬时的丢包。不过这种方法有个小副作用,那就是排队的包过多会增加处理网络包的延时。所以另外一种解决思路更好,那就是让内核处理网络包的速度更快一些,而不是让网络包傻傻地在RingBuffer中排队。
在数据被接收到RingBuffer之后,下一个执行的就是硬中断的发起。
硬中断的情况 cat /proc/interrupts
对于收包情况,硬中断的总次数 不等于 Linux收包总数。因为,第一网卡可以设置中断合并,多个网络帧只可以发起一次中断,第二NAPI运行时 会关闭硬中断,通过poll来收包。
目前主流网卡基本都是支持多队列的,可以通过将不同队列分为不同的CPU来处理,加快处理网络包的速度。(最为有用的一个优化手段)
每一个队列都有一个中断号,可以独立向某个CPU核心发起硬中断请求,让CPU来poll包。通过将接收进来的包被放到不同的内存队列里,多个CPU就可以同时分别向不同的队列发起消费了。这个特性叫做RSS(Receive Side Scaling,接收端扩展)。通过ethtool工具可以查看网卡的队列情况。
1 | ethtool -l eth0 |
如果你想提高内核收包的能力,直接简单加大队列数就可以了,这比加大RingBuffer更为有用。因为加大RingBuffer只是给个更大的空间让网络帧能继续排队,而加大队列数则能让包更早地被内核处理。ethtool修改队列数量方法如下:
1 | ethtool -L eth0 combined 32 |
对于CPU来讲也是一样,CPU要做一件新的事情之前,要加载该进程的地址空间,load进程代码,读取进程数据,各级别cache要慢慢热身。因此如果能适当降低中断的频率,多攒几个包一起发出中断,对提升CPU的工作效率是有帮助的。所以,网卡允许我们对硬中断进行合并。
1 | ethtool -c eth0 |
在硬中断之后,再接下来的处理过程就是ksoftirqd内核线程中处理的软中断了。之前我们说过,软中断和它对应的硬中断是在同一个核心上处理的。因此,前面硬中断分散到多核上处理的时候,软中断的优化其实也就跟着做了,也会被多核处理。不过软中断也还有自己的可优化选项。
1 | cat /proc/softirqs 可以查看软中断信息 |
这个的意思说的是,ksoftirqd一次最多处理300个包,处理够了就会把CPU主动让出来,以便Linux上其它的任务可以得到处理。那么假如说,我们现在就是想提高内核处理网络包的效率。那就可以让ksoftirqd进程多干一会儿网络包的接收,再让出CPU。至于怎么提高,直接修改不这个参数的值就好了。
1 | sysctl -w net.core.netdev_budget=600 |
如果要保证重启仍然生效,需要将这个配置写到/etc/sysctl.conf
GRO和硬中断合并的思想很类似,不过阶段不同。硬中断合并是在中断发起之前,而GRO已经到了软中断上下文中了。
如果应用中是大文件的传输,大部分包都是一段数据,不用GRO的话,会每次都将一个小包传送到协议栈(IP接收函数、TCP接收)函数中进行处理。开启GRO的话,Linux就会智能进行包的合并,之后将一个大包传给协议处理函数。这样CPU的效率也是就提高了。
1 | ethtool -k eth0 | grep generic-receive-offload |
大多数MCU都没有FPU 硬件浮点单元。如果用float double运算,编译器会调用软件库函数来模拟浮点加减乘除。需要分解成一系列整数操作,移位,比较,循环,效率非常低。可能要几十到上百条指令。
定点运算用的就是普通的整数运算单元。MCU内核天然支持整数加减乘除移位,一条指令就可以完成。
CPU如何进行浮点运算
IEEE754标准。浮点数分为 符号位,指数,尾数部分。没有FPU的MCU运算过程
1 | 取出指数和尾数。 |
cmake
官方教程地址
https://modern-cmake-cn.github.io/Modern-CMake-zh_CN/chapters/intro/running.html
生成Makefile的工具。需要攥写的是CMakeLists.txt。
1 | add_executable(one two.cpp three.h) 生成一个one可执行文件 |
debug命令
1 | --trace 选项能够打印出运行的 CMake 的每一行。 |
递归make。通过将源文件划分为不同的模块,组件。每个组件都由自己的makefile管理。开始构建时,顶级的makefile以正确的调用顺序调用每个组件的makefile。
kbuild指向到不同类型的makefile
Kbuild是linux的内核专用构建系统。依赖内核顶层Makefile和一堆构建脚本。单独拿出来几乎没意义。
在看linux的代码的时候,看到了很多关于backlog的说法,进而了解到linux下的back pressure机制。故在此记录下。
Applying Back Pressure When Overload,系统持续过载的处理手段,核心观点,限制队列长度。从而为队列中的任务维持系统高吞吐率和良好的响应时间。
在linux内核中。backlog是一个在多个子系统(网络协议栈,加密模块,块设备子系统)中的通用概念。本质上表示 “任务积压队列”或者“待处理任务的缓冲区”。虽然出现在不同的子系统中,但核心思想类似,都是当资源暂时不可用/系统无法立即处理即时任务时,将任务缓存在backlog中等待稍后处理。
backlog是一个临时存储结构,处理以下情况
通常,backlog会配合异步处理机制(软中断,工作队列)一起使用。
crypto api 中的 backlog 更多是异步请求的概念。
backlog一般具备以下机制。
| 机制组成 | 说明 |
|---|---|
| 队列结构 | 通常为链表,如 list_head,或环形缓冲区等 |
| 入队操作 | 当不能立即处理请求时,调用 enqueue() 将请求加入 |
| 出队处理 | 某个异步事件(如软中断、tasklet、workqueue)触发处理 |
| 并发控制 | 多用自旋锁或 RCU 保证并发安全 |
| 队列限流 | 使用最大队列长度(max_backlog)限制,防止 OOM 或 DoS |