未命名
每日一题,7.2
题目
1 | Alice 正在她的电脑上输入一个字符串。但是她打字技术比较笨拙,她 可能 在一个按键上按太久,导致一个字符被输入 多次 。 |
用到的算法
DP
把一个复杂问题拆成多个子问题,先解决子问题,保存结果,再从小到大解决整个问题。
区间DP
当你的问题需要处理一段区间,比如字符串的一部分,数组的一段,那么通常使用区间动态规划。Interval DP。
背包问题
属于DP模型之一。
| 类型 | 特点 |
|---|---|
| 0-1 背包 | 每个物品只能选一次 |
| 完全背包 | 每个物品可以选无数次 |
| 多重背包 | 每个物品最多只能选 cnt 次 |
前缀和
1 | s[i] = f[0] + f[1] + ... + f[i]; |
差分前缀转移
如果你想枚举从上一个阶段状态转移过来,比如,当前字符段长度为cnt,当前字符串要变成长度j,你只能从长度在 [j-cnt,j-1] 的状态转移过来。
传统做法是
1 | for (int t = 1; t <= cnt; ++t) { |
优化做法是
1 | f_new[j] = g[j - 1] - g[j - cnt - 1]; // 差分区间快速求和 |
题解
未命名
linux irq
GIC控制器
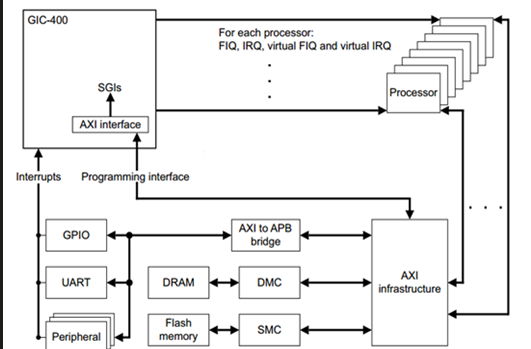
Generic Interrupt Controller。ARM提供的通用中断控制器。接受硬件中断信号,并经过一定处理后,分发给对应的CPU进行处理。分为V1-V4,
GICV2
GIC是联系外设中断和CPU的桥梁,也是各CPU之间中断互联的通道,负责检测,管理,分发中断。
1 | 主要负责 |
ARM CPU对外的连接只有2个中断,IRQ & FIQ,相对应的处理模式分别是 IRQ 一般中断处理模式 和 FIQ 快速中断处理模式,所以GIC最后要把中断汇集成2条线,与CPU对接。
在GICV2中,gic由两个大模块distributor和interface组成。
distributor
主要负责中断源的管理,优先级,中断使能,中断屏蔽等。中断分发,对于PPI,SGI是各个core独有的中断,不参与目的core的仲裁,SPI 是所有 core 共享的,根据配置决定中断发往的core。中断优先级的处理,将最高优先级的中断发送给cpu interface。寄存器使用GICD作为前缀,一个gic中,只有一个GICD。
主要的作用是检测各个中断源的状态,控制各个中断源的行为,分发各个中断源产生的中断事件到指定的一个/多个CPU接口上。虽然分发器可以管理多个中断源,但是它总是把优先级最高的那个中断请求送往CPU接口。分发器对中断的控制包括:
1 | 打开或关闭每个中断,Distributor对中断的控制分成两个级别,一个是全局中断的控制(GIC_DIST_CTRL),一旦关闭了全局中断,那么任何的中断源产生的中断事件都不会被传递到cpu interface。另一个级别是针对各个中断源进行控制,(GIC_DIST_ENABLE_CLEAR),关闭一个中断源会导致该中断事件不会分发到CPU interface,但不影响其他中断源产生中断事件的分发。 |
cpu interface
用于连接器,与处理器进行交互,将GICD发送的中断信息,通过IRQ,FIQ等管脚,传输给core。寄存器使用GICC作为前缀,每一个core,有一个cpu interface。
1 | 打开或关闭cpu interface 向连接的CPU assert中断事件,对于arm,cpu interface和cpu之间的中断信号线是nIRQCPU 和 nFIQCPU, 如果关闭了中断,即便是distributor分发了一个中断事件到CPU interface,也不会assert指定的IRQ或者FIQ通知core。 |
virtual cpu interface
将GICD发送的虚拟中断信息,通过VIRQ,VFIQ管脚,传输给core,每一个core,有一个virtual cpu interface,而在这个virtual cpu interface中,又包含以下两个组件,virtual interface control,virtual cpu interface。
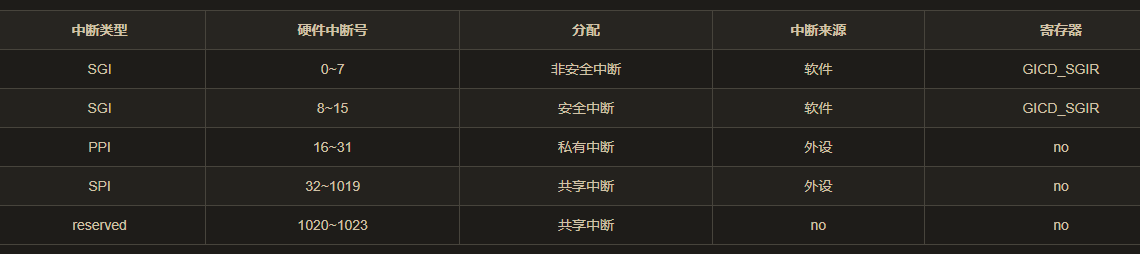
gic中断类别
gicv2,将中断,分成了group0,安全,FIQ 和group1,非安全,IRQ。
支持三种类型的中断。
1 | GICV2: |
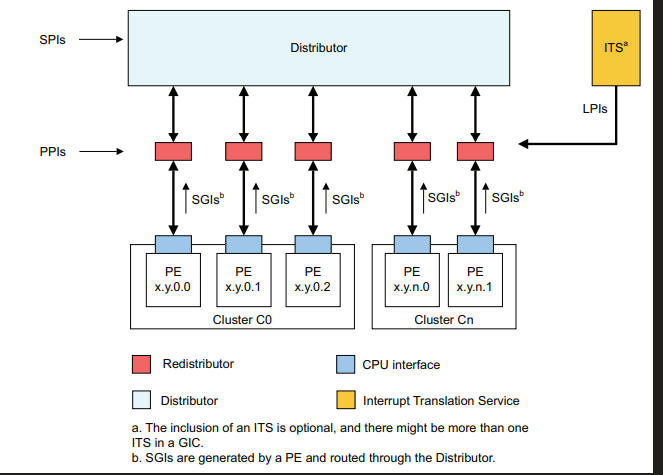
GICV3的组成部分,GICV3中,主要由Distributor,cpu interface,redistributor,its,GICV3中,将cpu interface从GIC中抽离,放入到了cpu中,cpu interface通过AXI Stream,与gic进行通信。 当GIC要发送中断,GIC通过AXI stream接口,给cpu interface发送中断命令,cpu interface收到中断命令后,根据中断线映射配置,决定是通过IRQ还是FIQ管脚,向cpu发送中断。
1 | root@root:~# cat /proc/interrupts |
gic中断处理流程
1 | GIC决定每个中断的 使能 状态,不使能的中断,是不能发送中断的 |
gic中断优先级
gicv2,支持最小16个,最大256个中断优先级。
中断状态和处理流程
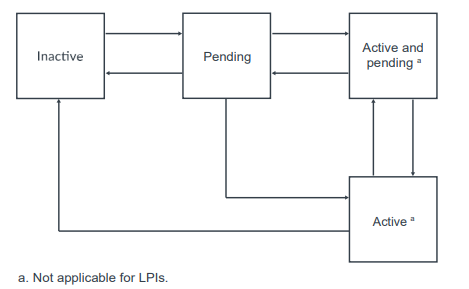
1 | 每个中断都维护了一个状态机。 |
软件框架
1 | 主要分为四部分: |
1 | 常见术语 |
中断设备树
1 | gic: interrupt-controller@fd400000 { |
中断控制器code
1 | IRQCHIP_DECLARE(gic_v3, "arm,gic-v3", gicv3_of_init); //初始化一个struct of_device_id的静态常量,并放置在__irqchip_of_table中 |
1 | https://doc.embedfire.com/linux/rk356x/driver/zh/latest/linux_driver/subsystem_interrupt.html |
中断上下部分的处理手段
运行在进程上下文的内核代码是可抢占的,但中断上下文会一直运行到结束,不会被抢占。所以中断处理程序代码要受到一些限制。
1 | 中断代码不能: |
linux_network_1
socket的创建
1 | SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol) |
内核和用户进程之间阻塞
同步阻塞/recvfrom
1 | 同步阻塞的开销主要有: |
多路复用epoll
1 | epoll_create |
1 | 本质上是 极大程序的减少了无用的进程上下文切换,让进程更专注处理网络请求。 |
1 | epoll也是阻塞的。没有请求处理的时候,也会让出CPU。阻塞不会导致低性能。过多的阻塞才会。W |
阻塞 非阻塞
阻塞指的是进程因为等待某个事件而主动让出CPU挂起的操作。在网络IO中。当进程等待socket上的数据时,如果数据还没有到来,那就把当前状态从TASK_RUNNING修改为TASK_INTERRUPTIBLE。然后主动让出CPU,由调度器来调度下一个就绪状态的进程来执行。
所以,以后分析是否阻塞就看是否让出CPU。
内核是如何发送网络包的?
网络包发送过程总览
用户进程在用户态通过send系统调用接口进入内核态,send通过内存拷贝skb,进程协议处理进入驱动ring buffer,通过pci总线发送后,产生中断通知发送完成,并清理ring buffer。
1 | send |
数据发送完毕后,释放缓存 队列等内存。在网卡发送完毕后,给CPU发送一个硬中断来通知cpu。实际是触发了 NET_RX_SOFTIRQ 。所以服务器中proc softirqs里面NET_TX要比RX大很多。
网卡启动准备
网卡启动最重要的任务之一就是分配和初始化RingBuffer。在对应的驱动程序的open函数中,对于ringbuffer进行分配。
1 | igb_setup_all_tx_resources |
为什么要用环形队列?好处是什么
| 特性/对比点 | 环形队列(Ring Buffer) | 普通 FIFO 队列(如链表) |
|---|---|---|
| 内存分配方式 | 预分配,连续内存块 | 动态分配,每个节点独立分配 |
| 缓存命中率 | 高(连续内存 + 局部性好) | 低(指针跳转 + 内存分散) |
| 指针操作复杂度 | 简单,仅需要 head 和 tail | 操作复杂,涉及节点申请/释放 |
| 支持无锁操作 | 易于 lockless 实现,尤其单生产者/单消费者模型 | 难,容易涉及竞态和锁 |
| 空间使用效率 | 高,数组固定大小,空间紧凑 | 较低,节点指针额外开销 |
| 硬件 DMA 支持 | 很多硬件直接支持环形 DMA 描述符结构 | 不适用于 DMA 映射 |
| 数据结构大小固定性 | 是,数组固定大小,易于调优和估算 | 否,链表大小动态变化,管理麻烦 |
| 实现难度 | 结构简单,逻辑清晰 | 相对复杂,需要考虑链表指针等各种异常处理 |
数据从用户进程到网卡的过程
send系统调用实现
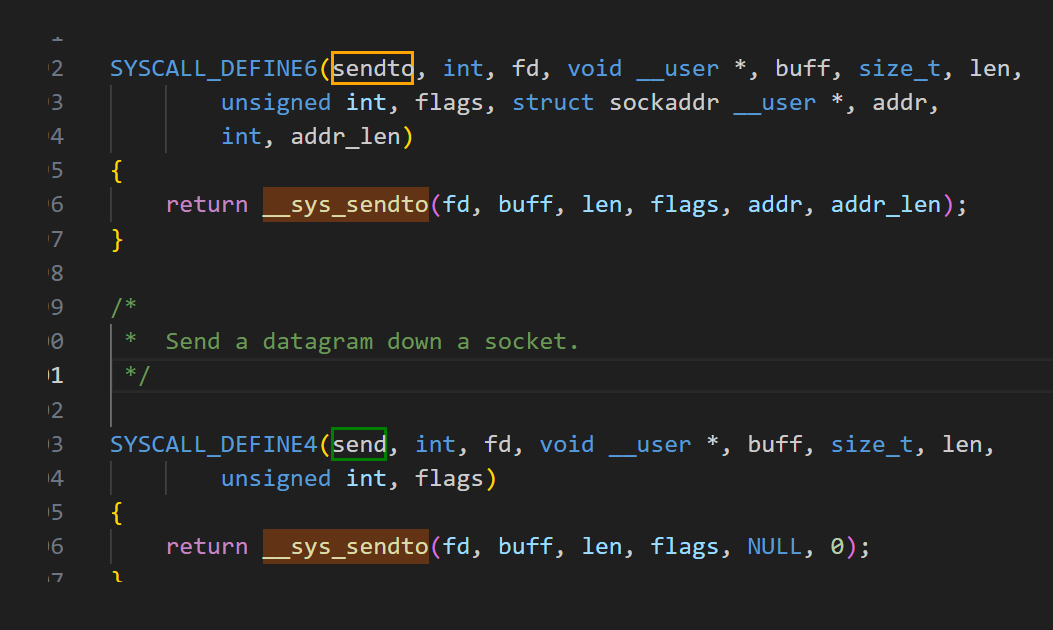
sendto中 构造 找到sock,构造msg后 通过 __sock_sendmsg 发送,到sock_sendmsg_nosec中,通过 inet6_sendmsg 调用进入协议栈。
传输层处理
在进入协议栈后,会找到具体的发送函数。对tcp来说是 tcp_sendmsg –> tcp_sendmsg_locked。 tcp_write_queue_tail获取发送队列的最后一个skb。把用户内存里的数据拷贝到内核态,涉及到1次/几次内存拷贝的开销。
1 | if (forced_push(tp)) { |
调用tcp_push_one / __tcp_push_pending_frames 将数据包发送出去。
最终会调用到。
1 | /* Send _single_ s |
网络层发送处理
tcp_write_xmit内部处理了传输层的拥塞控制,滑动窗口相关的工作,满足窗口要求的时候,设置TCP头然后将skb传到更低的网络层进行处理。
tcp_transmit_skb开启真正的发送函数。clone新的tcp出来,封装tcp的头.
1 | /* Build TCP header and checksum it. */ |
为什么要进行clone? tcp支持超时重传, 在收到对方的ACK之前,这个skb’不能被删除.等收到ACK后再次删除.
tcp_options_write中对TCP头进行设置, skb中包含了网络协议中的所有头,在设置TCP的头的时候,只需要把指针指向skb的合适位置,后面设置IP头的时候,指针在挪一挪即可.避免频繁的内存申请拷贝.
1 | queue_xmit 在 ipv4中 实际值得是. |
邻居子系统
位于网络层和数据链路层中间的一个系统, 为网络层提供一个下层的封装, 让网络层不必关心下层的地址信息, 让下层决定发送到哪个MAC地址. 主要查找/创建邻居项,在创建邻居项的时候,可能会发出实际的ARP请求,然后封装MAC头,将发送过程传递到更下层的网络设备子系统.
调用 neigh_resolve_output 发出,有可能触发arp请求.
最后调用 dev_queue_xmit 将skb传递给Linux网络设备子系统
linux网络设备子系统
__dev_queue_xmit()
└── __dev_queue_xmit_xmit()
└── dev_hard_start_xmit()
└── xmit_one()
└── dev->netdev_ops->ndo_start_xmit()
总览
TX
1 | // 1.分配 sk_buff,复制用户数据 |
RX
1 | 1. 软中断 |
参考资料
https://blog.csdn.net/weixin_44260459/article/details/121480230

tcpdump抓包?

主要通过libpcap库实现,内部通过BPF技术实现数据过滤。将用户定义的过滤条件以字节码的形式注入内核, 由内核层筛选网络包后,将满足条件的包交给用户态处理。
tcpdump通过 AF_PACKET socket 接收以太网帧;工作在链路层。

未命名
linux的密码管理
在linux内核中,密码相关的头文件在 include crypto下,相关概念大致有加密 块加密 异步块加密 哈希 分组加密模式等等。
加密算法
算法:
AEAD算法:一种带有认证功能的加密方式。拆分为认证和加密两部分。常见的有GCM和CCM,
对称加密算法: 使用同一个密钥进行加密和解密。这意味着加密方和解密方必须事先共享同一个密钥,并且保证这个密钥的安全。
AES:AES-128 AES-256等,后个字段对应密钥长度。密钥越长,安全性能越高,加密时间越长。
DES,3DES等。
非对称加密算法: 使用一对密钥,一个公开密钥(公钥)用于加密,一个私有密钥(私钥)用于解密。公钥可以公开分享,而私钥必须保持私密。
模式:
实现不同的算法有几种模式:
主要有ECB CBC CFB OFB 和 CTR等这几种。
不同模式的区分如下:
ECB模式: ECB是最简单的块密码加密模式,加密前根据加密块大小(如AES为128位)分成若干块,之后将每块使用相同的密钥单独加密,解密同理。
CBC模式: CBC模式对于每个待加密的密码块在加密前会先与前一个密码块的密文异或然后再用加密器加密。第一个明文块与一个叫初始化向量的数据块异或。
CFB模式: 与ECB和CBC模式只能够加密块数据不同,CFB能够将块密文(Block Cipher)转换为流密文(Stream Cipher)。
OFB模式: OFB是先用块加密器生成密钥流(Keystream),然后再将密钥流与明文流异或得到密文流,解密是先用块加密器生成密钥流,再将密钥流与密文流异或得到明文,由于异或操作的对称性所以加密和解密的流程是完全一样的。
CTR模式: CTR模式是一种通过将逐次累加的计数器进行加密生成密钥流的流密码。
加密算法在内核中的形式
以aes加密算法为例。

所有的加密算法名都是xxx_alg的方式。关键成员有算法名 驱动名 算法类型 同步,异步,分组大小,上下文。加解密函数等等。
在alg结构中,块加密和普通分组加密的区别就是.cra的设置。普通分组加密指定的是cipher.同步块加密指定的是blkcipher. 异步块加密指定的是ablkcipher。
ctx:上下文。指的是算法执行过程中所要贯穿始终的数据结构。由每个算法自己定义。set_key encrypt decrypt这几个函数都可以从参数获得算法上下文的指针。算法上下文所占的内存空间由密码管理器来分配。注册alg的时候指定ctx大小和对其即可。ctx对齐对于一些硬件加密等。ctx的首地址可能需要在内存中4字节或者16字节对齐。
Device Mapper
device mapper是linux 2.6内核中支持的逻辑卷管理的通用设备映射机制。为实现用于才能出资源管理的块设备驱动提供了一个高度模块化的内核架构。

在内核中它通过一个一个模块化的target driver实现对IO请求的过滤或者重定向。包括软raid,软加密,多路径,镜像,快照等等。device mapper用户空间相关部分主要负责配置具体的策略和控制逻辑。比如逻辑设备和哪些物理设备映射。怎么建立这些映射关系等等。而具体的过滤和重定向IO请求的工作由内核相关代码完成。整个device mapper机制由两部分组成 内核空间的device mapper驱动,用户空间的device mapper库以及他提供的dmsetup工具。
内核部分
device mapper的内核相关代码在driver/md目录中。device mapper在内核中作为一个块设备驱动被注册的,包含三个重要的对象概念,mapped device,映射表,target device。
mapped device是一个逻辑抽象,是内核向外提供的逻辑设备。通过映射表描述的映射关系和target device建立映射。从mapped device 到一个 target device的映射表由一个多元组表示,该多元组由表示mappdevice逻辑的起始地址,范围,和表示在target device所在的物理设备的地址偏移量以及target类型等变量组成。以磁盘扇区为单位,512字节大小。
target device表示的是mapped device所映射的物理空间段。device mapper中这三个对象和target driver一起构成了可迭代的设备树 。
用户空间部分
Device mapper在用户空间包括device mapper库和dmsetup工具,device mapper库就是对ioctl 用户空间创建删除devicemapper逻辑设备所需必要操作的封装。dmsetup工具是一个应用层直接操作device mapper设备的命令行工具。大致包含,发现每个mapper device相关的target device,根据配置信息创建映射表,将用户空间构建好的映射表传入内核,让内核构建mapper device对应的dm table结构。
LUKS介绍
LUKS (linux unified key setup),linux统一密钥设置。是一种高性能安全的磁盘加密方法。基于cryptsetup。使用dm-crypt作为磁盘加密后端。
定义了如何安全存储加密密钥和加密元数据。支持多重密码。最多8个key slot。不需要重加密就能够更换密码。配合dm-crypt使用。实际加密使用的是内核支持的加密算法,LUKS只负责配置,封装和密钥管理。
LUKS结构

任何文件系统都可以加密,包括交换分区,加密卷的开头有一个未加密的头部。允许存储多达8个lusk1或者32个lusk2加密密钥,以及诸如密码类型和密钥大小之类的加密参数。
dm crypt
dm crypt,内核提供的磁盘加密功能。即device mapper crypto。lucks通过dmcrypt模块使用内核设备映射器子系统。负责处理设备的加密和解密。
cryptsetup
命令行的前端,通过它来操作 dm crypt。创建和访问加密设备。
linux加密框架
分成User Space layer 和 kernel Space layer。
kernel space.
在kernel space密码学算法上。主要分成软件以及硬件运算。
软件运算。主要由CPU进行密码学算法运算,不需要额外硬件,但很费CPU性能。linux kernel 原始码位于crypto subsystem下。
硬件加速。由硬件辅助进行密码学运算,不需要耗费cpu性能,但需要额外硬件。
SoC Component–许多ARM SoC厂商都会将硬件加解密元件放入SoC中,Linux Kernel原始码多位于drivers/crypto底下.且设计必须遵照Linux crypto framework,不能私下修改。
Crypto API User space interface
主要的功能是提供界面。让user space可存取kernel space.目前主流为cryptodev以及af_alg
crypt dev
不在linux kernel中自带。开源模块。需要单独移植,并挂载kernel module。
ioctl
openssl支持cryptodev。通过操作cryptdev节点来操作加密
af_alg
netlink
openssl从1.1开始支持af_alg。
User Space密码学库
常见的有openssl,wolfssl。
openssl提供af alg以及cryptdev的engine,可以透过engine来存取crypto api。
PART ONE Crypyo Subsystem of Kernel
介绍由应用层所发出的crypto(cryptography)request,透过system call将request传送到Linux kernel端,并经由crypto subsystem将request转发给硬件算法引擎(hardware crypto engine)的流程。
概述
Crypto subsystem是Linux系统中负责处理crypto request的子系统,除了包含流程控制机制之外,另一个重要特色就是提供算法实作的抽象层,让各家厂商能够依据需求去客制化实作方式。
其中一个常见例子就是厂商在硬件构架中加入用以加速特定算法运算效率的硬件算法引擎,并且透过crypto subsystem将驱动硬件算法引擎的流程整合进Linux系统中,供其他kernel module或是应用层使用。

cryptodev engine
在Linux系统中,想要实现应用层与硬件装置的沟通,第一个想到的就是透过character/block device driver,让应用程序开启表示此硬件装置的抽象层,并且藉由读写行为与硬件装置进行互动。
而Cryptodev-linux就是负责此角色,它提供中间层的服务,接收由应用层传送过来的crypto request,再呼叫Linux kernel crypto Subsystem的crypto API将request转发给特定的硬件算法引擎。
Cryptodev-linux为misc device类型的kernel module,预设路径是/dev/crypto,使用ioctl file operation cryptodev_ioctl来接受应用端所传递过来的数据。

应用端则是使用cryptdev.h定义好的struct crypt_op或是struct crypt_auth_op来组成指定crypto request,并呼叫ioctl system call将request送给Cryptodev-linux。
simple of cryptdev linux ioctl

另外,Cryptodev-linux也提供session机制,每个crypto request对应到一个session,而session管理当前crypto request的状态。
例如,目前session在initialized的状态,则表示此crypto request可执行encrypt,透过此方式来确保crypto request会在正确的流程下运作。
linux kernel crypto subsystem

首先 crypto subsystem有两个重要元素,transformation object(tfm),被称作cipher handle,transformation implementation,是transformation object底层的实作内容,又被称为crypto algo。就是crypto engine算法实作。
之所以要区分成object和implementation,最主要的原因是有可能多个object会使用同一个implementation。
举例来说,A和B使用者都要使用hmac-sha256算法,因此会新建立A和B两个transformation object并包含A和B各自拥有的key值,但这两个object有可能会使用同一个transformation implementation来呼叫同一个crypto engine进行算法运算。

当有crypto request进来,会先根据request中指定的算法名称,从已注册的crypto algorithm list中取出适合的crypto algorithm,并新建立transformation object。
之后,transformation object会再被组成crypto subsystem所用的cipher request。cipher request有可能共享同一个transformation object,举例来说,hmac-sha256的transformation object包含了transformation implementation和一个key值,而这个transformation object可以使用在多个cipher request的messsage上进行hash算法。当cipher request完成相关设值之后,接着实际调用transformation object的transformation implementation执行算法运算。
此时会出现一个问题,就是当短时间有多个request进来时,我们该如何依序地处理request?
这点crypto subsystem也设计了方便的struct crypto_engine,crypto engine提供了queue管理机制,让多个request能够顺序地转发给对应的crypto engine。
要新增transformation implementation到crypto subsystem,最重要的就是注册transformation implementation到crypto algorithm list中。

使用crypto_register_skciphers即可完成注册。
另外,cra_priority代表各算法的优先程度,优先级高的会先被采用。
asynchronous & synchronous
在crypto subsystem中,crypto API分成asynchronous(异步)和synchronous(同步)两种机制。
最早版本的crypto API其实只有synchronous crypto API,但随着要处理的数据量增加,运算和数据传输时间也可能大幅拉长,此时synchronous crypto API有可能让处理流程陷入较长时间的等待,因此后来引入了asynchronous crypto API,供使用者依据自己的使用场景来选择适合的机制。
而asynchronous与synchronous crypto API在命名设计上有所区别,asynchronous会在前缀多加一个a字,反之synchronous则是s字,以hash为例:

synchronous api

只要顺序的呼叫对应流程的API,并且针对返回的结果进行error handling即可。
在API的呼叫流程中,crypto_shash_update可以被多次呼叫,让使用者放入多组需要进行加密的message。当完成一组message后,可能有些中间状态是需要被保存起来的。这些状态就会存在state handler中。在使用者呼叫api前,会需要自己分配一块足够大小的内存,让crypto engine能够存放这些状态。在transformation implementation中会设定好crypto engine需所需的状态存储空间大小,使用者只需要呼叫特定API即可。

除了命名之外,由于两种机制的处理流程不同,因此所需的参数也会有所不同。
async request

包含一个callback function crypto completion,当运算完成后,会透过此callback来通知使用者继续处理完成的流程。由于asynchronous非同步机制,因此crypto engine在处理request时,行为和流程也和synchronous同步机制有蛮大的差异,其中常见的实作方式加入request queue来管理多个request,当使用者呼叫update API发送request时,则会将request加入到queue中,并直接回传处理中(-EINPROGRESS)的状态信息。
如果使用者使用asynchronous hash API,但是实际上对应的transformation implementation却是synchronous型态,crypto subsystem会主动进行相关的数据转换,因此也是可以正常运作的。
一般常见的方式是 crypto queue搭配worker,额外开一个kernel thread来与crypto engine进行沟通,让crypto request按照FIFO的顺序处理。

建立一个全局的crypto request list,将进来的request依序排到list中,建立一个worker(kernel thread)和对应的work queue来与hardware crypto engine进行沟通,worker的任务除了从crypto request list中取出request处理h之后,也可能会包含crypto engine的初始化和资源释放等工作。注册interrupt handler,当status interrupt举起时,呼叫user自定义的completion callback function来完成最后的流程。
crypto/engine.h中有提供接口可以直接调用。

hwmon
概述
hwmon,hardware monitor是linux内核中的一个子系统,用于提供对硬件设备,如温度传感器,电压监控器,风扇速度等的监控支持。该子系统允许用户通过标准的接口读取和控制硬件状态。尤其是温度,电压,风扇转速等。提供了统一的方式访问硬件监测信息。
hwmon子系统架构
在hwmon子系统中,主要即借助设备驱动模型中的设备的注册以及设备属性的创建,即可针对于一个硬件芯片创建多个属性文件。

hwmon子系统主要提供了接口hwmon_attr_show、hwmon_attr_store,同时抽象了针对温度芯片、风扇芯片、电源芯片等硬件监控芯片相关参数的支持,即温度芯片、风扇芯片、电源芯片等硬件监控芯片相关参数的访问接口,均会在接口hwmon_attr_show、hwmon_attr_store中被统一调用,而温度芯片、风扇芯片、电源芯片等硬件监控芯片只需要实现hwmon_ops类型函数指针即可。调用关系如下所示,其中,HWMON子系统层则为hwmon子层抽象的部分,而最下层则由具体的hwmon 设备驱动实现即可。

硬件检测
1 | devm_hwmon_device_register_with_groups(dev, "my_hwmon", NULL, my_temp_attr); |
数据读取/设置
1 | sensor_device_attribute |
数据暴露
sys/class/hwmon下暴露。
1 | cat /sys/class/hwmon/hwmon0/temp1_input # 获取温度 |
驱动卸载
1 | void hwmon_device_unregister(struct device *dev); |
linux_phy_reg
本文章介绍linux下应用层访问phy寄存器的几种方式 便于开发者开发
厂家提供节点
一些厂家会直接提供类似/dev/mdio类似的节点,可以find -name 搜索一下看看。通过操作节点可以直接操作phy寄存器
uboot
uboot下可以通过mii cmd来实现读写phy寄存器
ioctl
套接字
API
1 | /* 成功时返回文件描述符,失败时返回-1 |
协议族
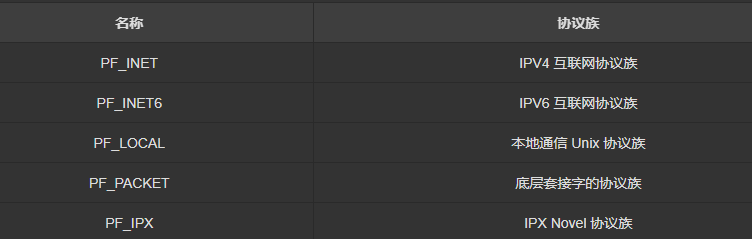
套接字类型
常用:
SOCK_STREAM:
流,TCP。面向连接。
- 传输过程中数据不会消失。
- 按序传输数据。
- 传输的数据不存在数据边界(Boundary)。
- 缓冲区不会因为满而丢失数据,因为有滑动窗口控制,能接收多少都会告诉对端。
SOCK_DGRAM
面向消息的,不可靠的。
- 强调快速传输而非传输有序。
- 传输的数据可能丢失也可能损毁。
- 传输的数据有边界。
- 限制每次传输数据的大小。
ioctl实现
1 | LONG skfd = -1; |
底层调用实现
1 | // 内核通用框架 |