Bloom_filter
布隆过滤器介绍
基本概念:它实质上是一个很长的二进制向量和一系列随机映射函数 (Hash函数)。
作用:它是一个空间效率高的概率型数据结构,用来告诉你:一个元素一定不存在或者可能存在。
优点:
在存储空间和时间都是常数,即hash函数的个数Hash 函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。布隆过滤器可以表示全集,其它任何数据结构都不能。
缺点:
- 有误判率存在
- 不支持删除
适用场景:
- 预防缓存穿透:布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在。
- 网络爬虫:布隆过滤器可以用来去重已经爬取过的URL。
- 邮箱的垃圾邮件过滤。
- 黑白名单。
原理
结构
布隆过滤器实现原理就是一个超大位数的数组(BitMap)和多个不同Hash算法函数。与寻常数组不同的是,BitMap一个数组元素占一个bit,这一特性决定了BitMap能够极大地节省空间。

添加元素
将要添加的元素分别通过k个哈希函数计算得到k个哈希值,这k个hash值对应位数组上的k个位置,然后将这k个位置设置为1。
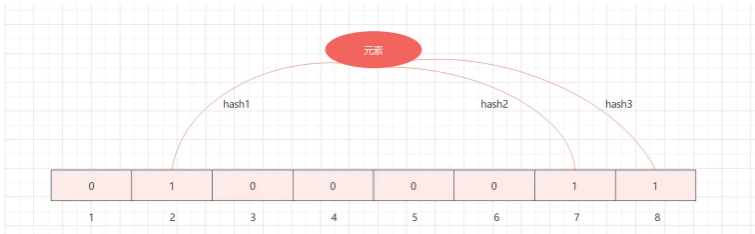
当不同元素在计算到相同的值后,依旧保持这一位为1即可。
查询元素
将要查询的元素分别通过k个哈希函数计算得到k个哈希值,这k个hash值对应位数组上的k个位置。如果这k个位置中有一个位置为0,则此元素一定不存在集合中。如果这k个位置全部为1,则这个元素可能存在。
误判
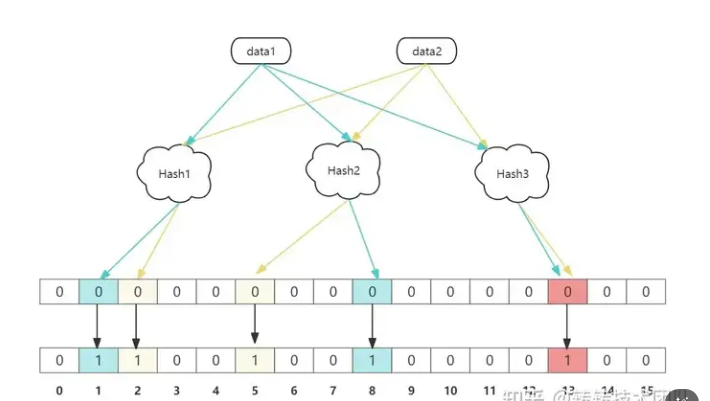
需要注意的是,布隆过滤器无法确定元素存在,只能确定元素不存在。出现的原因是多个输入经过哈希之后在相同的bit位置1了,这样就无法判断究竟是哪个输入产生的,因此误判的根源在于相同的 bit 位被多次映射且置 1。
这种情况也造成了布隆过滤器的删除问题,即布隆过滤器不存在删除操作。因为布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素。
应用场景
防止缓存穿透。缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。使用布隆过滤器能够避免频繁查询不存在的数据,减轻数据库的压力。
业务场景中判断用户是否阅读过某视频或文章,比如抖音或头条,当然会导致一定的误判,但不会让用户看到重复的内容。
gun hash表, 主要是利用 Bloom Filter, 在常量时间内判断, 字符是否存在, 以及对应 .dynsym 的位置. 使用 gcc -g -o hello -Wl,--hash-style=sysv(gnu) hello.c 可以产生旧版本的 hash 表.