emmc分区
emmc有默认四个物理分区。是出场即默认存在的。
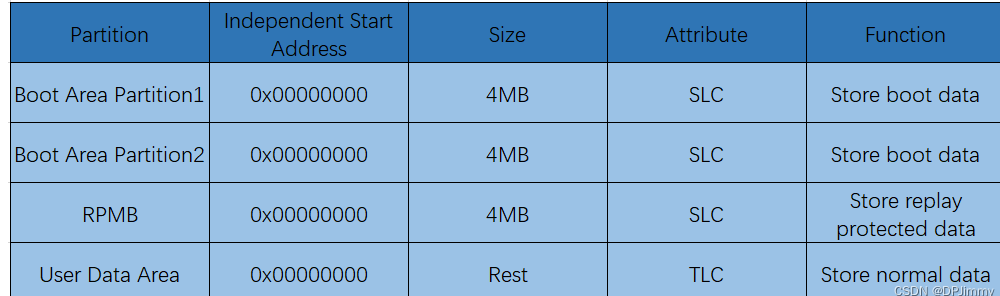
各个分区有独立的地址,都是从0x00开始的。Boot1,Boot2和RPMB的大小会在出厂的时候就设定好。两个boot的大小是完全一致的。由Extended CSD register的BOOT_SIZE_MULT Filed决定。大小的计算公式如下:

一般情况下,Boot Area Partition 的大小都为 4 MB,即 BOOT_SIZE_MULT 为 32,部分芯片厂家会提供改写 BOOT_SIZE_MULT 的功能来改变 Boot Area Partition 的容量大小。BOOT_SIZE_MULT 最大可以为 255,即 Boot Area Partition 的最大容量大小可以为 255 x 128 KB = 32640 KB = 31.875 MB。
分区编制
具体的数据读写访问操作实际访问哪一个硬件分区。是由EMMC 的 Extended CSC register的PARTITION_CONFIG Field 中 的 Bit[2:0]: PARTITION_ACCESS 决定的,用户可以通过配置来切换硬件分区的访问。
也就是说,用户在访问特定的分区前,需要先发送命令,配置 PARTITION_ACCESS,然后再发送相关的数据访问请求。
从Boot area启动
eMMC 中定义了 Boot State,在 Power-up、HW reset 或者 SW reset 后,如果满足一定的条件,eMMC 就会进入该 State。进入 Boot State 的条件如下:
Original Boot Operation
CMD 信号保持低电平不少于 74 个时钟周期,会触发 Original Boot Operation,进入 Boot State。
Alternative Boot Operation
在 74 个时钟周期后,在 CMD 信号首次拉低或者 Host 发送 CMD1 之前,Host 发送参数为 0xFFFFFFFA 的 COM0时,会触发 Alternative Boot Operation,进入 Boot State。
在 Boot State 下,如果有配置 BOOT_ACK,eMMC 会先发送 “010” 的 ACK 包,接着 eMMC 会将最大为 128Kbytes x BOOT_SIZE_MULT 的 Boot Data 发送给 Host。传输过程中,Host 可以通过拉高 CMD 信号 (Original Boot 中),或者发送 Reset 命令 (Alternative Boot 中) 来中断 eMMC 的数据发送,完成 Boot Data 传输。
Boot Data 根据 Extended CSD register 的 PARTITION_CONFIG Field 的 Bit[5:3]:BOOT_PARTITION_ENABLE 的设定,可以从 Boot Area Partition 1、Boot Area Partition 2 或者 User Data Area 读出。
Boot Data 存储在 Boot Area 比在 User Data Area 中要更加的安全,可以减少意外修改导致系统无法启动,同时无法更新系统的情况出现。
http://www.wowotech.net/basic_tech/emmc_partitions.html
RPMB Partition
Replay Protected Memory Block Partition是emmc中一个具有安全特性的分区。eMMC 在写入数据到 RPMB 时,会校验数据的合法性,只有指定的 Host 才能够写入,同时在读数据时,也提供了签名机制,保证 Host 读取到的数据是 RPMB 内部数据,而不是攻击者伪造的数据。
RPMB 在实际应用中,通常用于存储一些有防止非法篡改需求的数据,例如手机上指纹支付相关的公钥、序列号等。RPMB 可以对写入操作进行鉴权,但是读取并不需要鉴权,任何人都可以进行读取的操作,因此存储到 RPMB 的数据通常会进行加密后再存储。
容量大小
两个 RPMB Partition 的大小是由 Extended CSD register 的 BOOT_SIZE_MULT Field 决定,大小的计算公式如下:
Size = 128Kbytes x BOOT_SIZE_MULT
一般情况下,Boot Area Partition 的大小为 4 MB,即 RPMB_SIZE_MULT 为 32,部分芯片厂家会提供改写 RPMB_SIZE_MULT 的功能来改变 RPMB Partition 的容量大小。RPMB_SIZE_MULT 最大可以为 128,即 Boot Area Partition 的最大容量大小可以为 128 x 128 KB = 16384 KB = 16 MB。
Replay Protected 原理
使用 eMMC 的产品,在产线生产时,会为每一个产品生产一个唯一的 256 bits 的 Secure Key,烧写到 eMMC 的 OTP 区域(只能烧写一次的区域),同时 Host 在安全区域中(例如:TEE)也会保留该 Secure Key。
在 eMMC 内部,还有一个RPMB Write Counter。RPMB 每进行一次合法的写入操作时,Write Counter 就会自动加一 。
通过 Secure Key 和 Write Counter 的应用,RMPB 可以实现数据读取和写入的 Replay Protect。
User Data Area
通常是EMMC分区中最大的一个。在实际产品中共,是主要区域。
容量大小
容量大小不需要设置,在配置完其他区域之后,扣除Enhanced attribute损耗的容量,剩余的就是UDA的容量。
区域属性
eMMC 标准中,支持为 UDA 中一个特定大小的区域设定 Enhanced attribute。与 GPP 中的 Enhanced attribute 相同,eMMC 标准也没有定义该区域设定 Enhanced attribute 后对 eMMC 的影响。Enhanced attribute 的具体作用,由芯片制造商定义、
- Default, 未设定 Enhanced attribute。
- Enhanced storage media, 设定该区域为 Enhanced storage media。
在实际的产品中,UDA 区域设定为 Enhanced storage media 后,一般是把该区域的存储介质从 MLC 改变为 SLC。通常,产品中可以将某一个 SW Partition 设定为 Enhanced storage media,以获得更好的性能和健壮性。
命令说明
mmc dev [dev] [part]
切换物理分区。mmc 设备编号,第一个为 0 part: 0 表示不访问引导分区 1 表示访问引导分区 1(boot0) 2 表示访问引导分区 2(boot1)
eg:切换到引导分区 1 –> mmc dev 0 1
mmc bootbus [dev] [boot_bus_width] [reset_boot_bus_width] [boot_mode]
设置总线位宽。
mmc partconf [dev ] [boot_ack ] [boot_partition ] [partition_access]
设置启动分区,dev 为mmc设备编号。boot_ack为是否应答。boot_partition用户选择发送到主机的引导数据。partition_access用户选择要访问的分区。