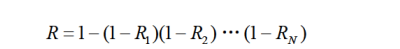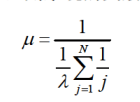netlink
什么是netlink?
netlink提供的是内核态和用户态之间的通信机制,也可以用于用户态和用户态的两个进程之间通信。
netlink的优势
一般的用户态和内核空间通信方式有三种,ioctl,proc,netlink。而前两种都是单向的,而netlink可以实现双向通信。基于BSD socket和AF_NETLINK协议簇。使用32位的端口号寻址。每个netlink协议,通常与一个或者一组内核服务/组件相关联。NETLINK_ROUTE用于获取和设置路由与链路信息、NETLINK_KOBJECT_UEVENT用于内核向用户空间的udev进程发送通知等。
netlink的特点
- 支持全双工,异步通信
- 在内核空间使用专门的内核api接口
- 支持多播,可以实现总线式订阅
- 在内核端可以用于进程上下文和中断上下文
- 用户空间使用标准BSD Socket接口
关键数据结构
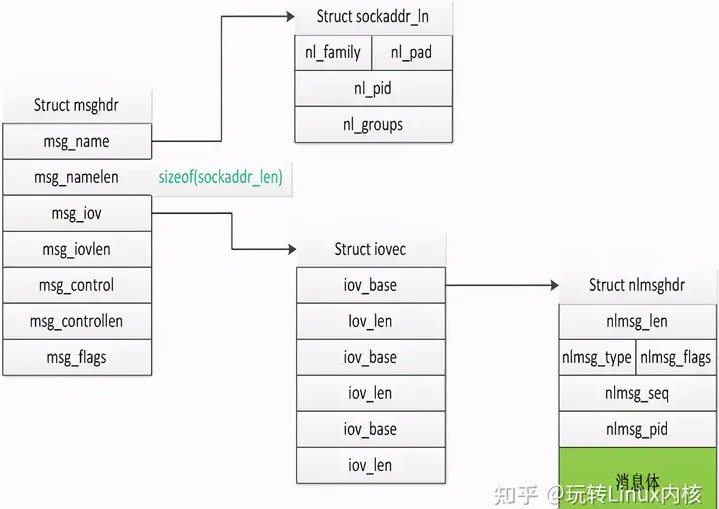
msghdr
我们知道socket消息的发送和接收函数一般有这几对:recv/send、readv/writev、recvfrom/sendto。当然还有recvmsg/sendmsg,前面三对函数各有各的特点功能,而recvmsg/sendmsg就是要囊括前面三对的所有功能,当然还有自己特殊的用途。msghdr的前两个成员就是为了满足recvfrom/sendto的功能,中间两个成员msg_iov和msg_iovlen则是为了满足readv/writev的功能,而最后的msg_flags则是为了满足recv/send中flag的功能,剩下的msg_control和msg_controllen则是满足recvmsg/sendmsg特有的功能。
sockaddr_nl
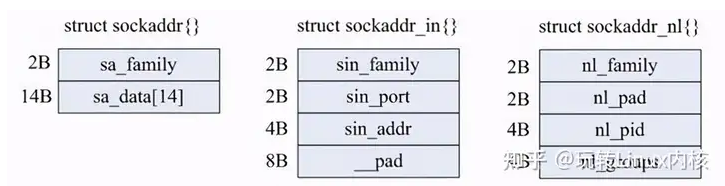
1 | struct sockaddr_nl |
struct nlmsghdr
netlink报文消息由头和消息体构成。
1 | struct nlmsghdr |
用户空间使用netlink
1.创建socket
1 | int socket(int domain, int type, int protocol) |
2.绑定netlink
1 | bind(fd, (struct sockaddr*)&, nladdr, sizeof(nladdr)); |
3.发送netlink消息
为了发送一条netlink消息到内核或者其他的用户空间进程,另外一个struct sockaddr_nl nladdr需要作为目的地址,这和使用sendmsg()发送一个UDP包是一样的。
- 如果该消息是发送至内核的,那么nl_pid和nl_groups都置为0.
- 如果消息是发送给另一个进程的单播消息,nl_pid是另外一个进程的pid值而nl_groups为零。
- 如果消息是发送给一个或多个多播组的多播消息,所有的目的多播组必须bitmask必须or起来从而形成nl_groups域。sendmsg(fd, &, msg, 0);
4.接收netlink消息
一个接收程序必须分配一个足够大的内存用于保存netlink消息头和消息负载。然后其填充struct msghdr msg,再使用标准的recvmsg()函数来接收netlink消息。
当消息被正确的接收之后,nlh应该指向刚刚接收到的netlink消息的头。nladdr应该包含接收消息的目的地址,其中包括了消息发送者的pid和多播组。同时,宏NLMSG_DATA(nlh),定义在netlink.h中,返回一个指向netlink消息负载的指针。调用close(fd)关闭fd描述符所标识的socket;recvmsg(fd, &, msg, 0);
内核空间使用netlink
创建netlink socket
1 | struct sock *netlink_kernel_create(struct net *net, |
发送单播信息
1 | int netlink_unicast(struct sock *ssk, struct sk_buff *skb, u32 pid, int nonblock) |
发送广播信息
1 | int netlink_broadcast(struct sock *ssk, struct sk_buff *skb, u32 pid, u32 group, gfp_t allocation) |
释放netlink socket
1 | int netlink_broadcast(struct sock *ssk, struct sk_buff *skb, u32 pid, u32 group, gfp_t allocation) |